December 2019
Microcode - Machine Language - Higher Level Language Example
It is too early to do this justice, but I wanted an example of how the different levels of code might compare. This example is very simple, as each version stores a decimal value of 4096 to a variable (assuming the variable is already setup so that it is usable). Variables are abstracted, but should work like registers, with the ability to read and write to them, perform math functions on them, etc.
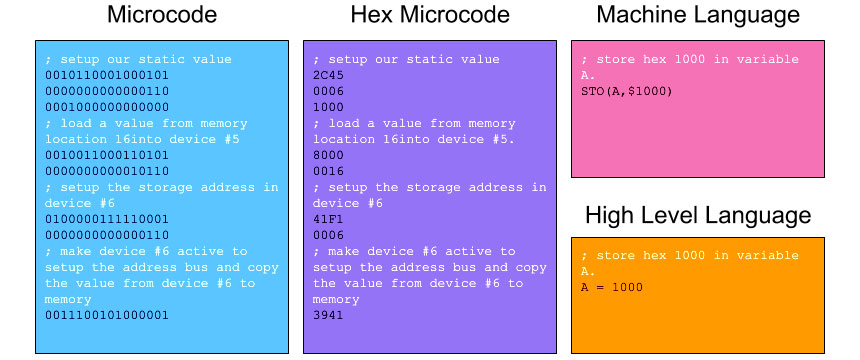
At a high level, we want to be able to say "put 1000 into variable A", but at lower levels we are forced to work with actual memory addresses, physical registers, etc. The difference in complexity is obvious, but to get to a high level language we need to write language functions (like variable read and write) in lower level code and then call them by their starting address in the firmware. Where higher level functions require passing values, we need to setup stacks or registers with the appropriate values so that the function will have what it needs. Functions will often need to update registers or locations in memory, so standards need to be developed and adhered to.
I will go into firmware memory segmentation in the next post, as it is an important concept to get across clearly.
Memory Segmentation and Firmware Plans
When I switched to a 16-bit data word, I had to rethink how instructions would work. Not at the lowest level, I still need to have ways to identify two registers and move data between them... but at a higher level. Can a branch be a single microcode instruction?
As a programmer, I like to think in terms of instructions, and some of the first programming I ever did was in 6502 machine language. Not assembly, I hand coded machine language by poking hex numbers into memory. To make my computer "usable", I need a way to get to a machine language level, so I can have a single instruction that can read or change a value in memory, or multiply two numbers, or compare the values of variables (instead of registers). Basically, I need a programming language. I also need a rudimentary operating system, to provide a bit of a framework for reading input, loading and saving programs, etc. To accomplish this, I am planning on segmented and overlapping memory, where 64K of SRAM and 64K of EEPROM occupies the same address space.
The user code space, in 64k of RAM, will be looked at in more detail at a later time, but it will probably contain some reserved blocks as well. The firmware side is the main subject of this post, so we will concentrate on that.
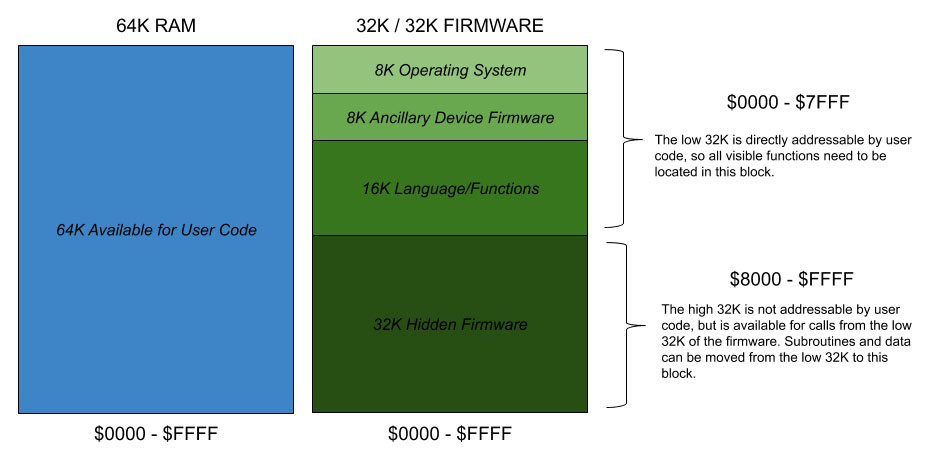
Instructions, in RAM, will include a 1-bit mode flag that will indicate whether it is a microcode instruction (see the "Parts of an Instruction" post for examples) or a language instruction call (basically, the starting address of a block of code in firmware). With 16-bit words, and a 1-bit mode flag, we have 15-bits remaining as a firmware address. This allows user available instructions to start in the low 32K of firmware. And additional 32K of "hidden" firmware is available for storing subroutines, code modules, and data required by instructions located in the user addressable space.
When a user program makes a call to a "language instruction" in firmware, the address is loaded into a separate firmware address pointer, leaving the PC pointing to the next instruction. The firmware address pointer will take over control of the computer, and will increment as microcode is loaded into the Instruction Register and executed. When a "return" is hit, the PC is activated again and the user program continues on. This basically allows users to mix microcode and higher level instructions at will. A future version may drop microcode support, at which time the entire 64K (or an additional bank, for 128K of Firmware) would be user addressable.
I considered having all user available instructions simply be addresses to the firmware, but 32k addressable seems like enough and I plan to build the language one instruction at a time in ram and move them to the firmware as they are perfected. That said, the goal is to have a simple high-level language based on basic, python, or c for users, with machine language mainly used to create new language instructions. Microcode probably will not be used in user programs once easier-to-use options are available.
I will give a theoretical example in the next post that will show how the same functionality could be implemented in the three levels of code. In a subsequent post, I will into more detail regarding the planned segmentation of the firmware into OS, reserved for peripherals, and language blocks. Planning ahead of time will make things much easier to work with later.